

Recap
In my previous post I reviewed the basics of conflict resolution in the Dropbox Datastore API. Go read it if you haven’t already.
Oh, OK, I’ll summarize. Changes to datastores are transferred between clients and server in the form of deltas. When two devices both change the contents of a datastore simultaneously, or while one or both of the devices are offline, the server will detect aconflict when the second device connects and attempts to upload its delta. The conflicting delta is rejected without prejudice. The device then has to resolve the conflict and send the server the new delta.
I left you with the promise I would show how the client library resolves “interesting” conflicts, a.k.a. collisions, where two devices attempt to change the contents of the same record.
Basic Conflict Resolution Algorithm
Here’s the basic algorithm the SDK currently uses for conflict resolution. In the future we hope to offer a more flexible API for your application to influence the outcome. We may also change the default treatment of field deletions (see below).
The basic conflict resolution algorithm considers one local change and one remote change, where a “change” is an insert, update or delete operation on a single record. A single change may affect multiple fields of the same record. The starting point for the algorithm, at least conceptually, is a snapshot of the datastore for which either change is valid. The output consists of three things: a new snapshot, and “rebased” versions (to borrow a term popularized by Git) of the original local and remote changes.
Here’s a picture. By convention, I will draw all local changes as arrows (edges) pointing down, and all remote changes as arrows pointing right. The original state is always represented by the the top left corner (node), and the original changes emanate from this point. The final outcome is shown at the bottom right corner, and the rebased changes are those at the bottom and right of the diagram. We sometimes call such a diagram a “square”:
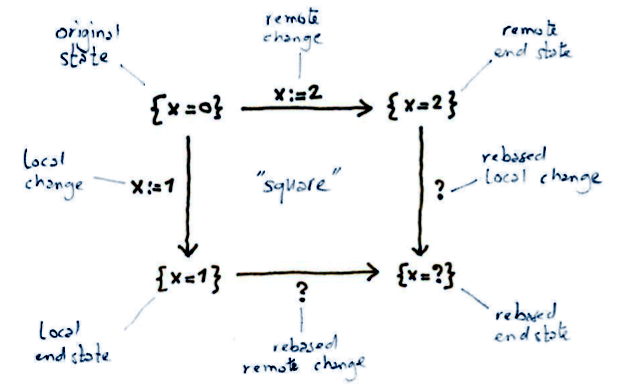
I’ll show how multiple changes are resolved further down.
Before the interesting stuff happens, the algorithm weeds out some easy cases:
- If the table IDs affected by local and remote change differ, the changes commute.
- If the record IDs differ, the changes commute.
- If one change deletes the record and the other updates it, the deletion wins.
- If both are record deletions, the local deletion disappears, being redundant.
- Updates are merged by field, as explained below.
As you may recall from part one, if two changes commute it doesn’t matter in which order we apply them. Two updates to the same record that change different fields also commute; for example:
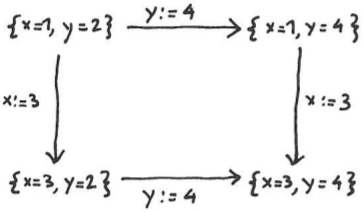
Similarly, if one change is said to “win” the outcome is obvious:

Note that deleting a record prevails over an update to the same record; the motivation for this behavior is that operations at a "higher level" should win over operations at a "lower level", and a record deletion operates at a higher level than a field update.
I will now describe what happens when two updates to the same record touch the same field. Let's call this a field collision. Since the algorithm takes everything one field at a time, there are no additional surprises for multiple field collisions, and you've already seen what happens to fields that are affected by only one of the two changes.
For field collisions we look at the type of the modifications and the resolution rule set for the field. We also distinguish between local and the remote changes. When resolving a conflict between two changes, one is always designated the local change: this is the one that hasn't been accepted by the server yet (in the first example above, this is "x:=1"). The change that was received from the server is called the remote change (in the example, "x:=2"). The difference is important because remote changes may already have been observed by other devices. This is also the reason why "remote" is the default rule (see below).
So how do we resolve the collision in this example? We look at the resolution rule for this field. As you may recall from the docs, there are five possible resolution rules. In this example (local x:=1, remote x:=2), the following table gives the algorithm's output:
| Rule | rebased local | rebased remote | rebased end state |
|---|---|---|---|
| remote (default) | NOP (loses) | x:=2 (wins) | {x=2} |
| local | x:=1 (wins) | NOP (loses) | {x=1} |
| max | NOP (loses) | x:=2 (wins) | {x=2} |
| min | x:=1 (wins) | NOP (loses) | {x=1} |
| sum | x:=3 | x:=3 | {x=3} |
It should be pretty clear now how all this works. NOP, of course, means "No Operation", a.k.a. the null change, which is substituted for an operation that loses or disappears completely.
The only case deserving some more explanation is the sum rule. This "reinterprets" the changes as additions to the field value in the original state. Since we (conveniently :-) started out with x equal to 0, this rewrites "x:=1" as "add 1 to x" and "x:=2" as "add 2 to x". When taken as additions, these changes "commute", with a combined effect of "add 3 to x" which sets the final value of x to 3 (phew!). However, the server doesn't actually understand "add" instructions, so we have to rewrite these back as plain assignments. This rewrites both add operations to "x:=3" (check the values at the intermediate states to verify that this all makes sense) and we get the following result, which matches the sum line in the above table:
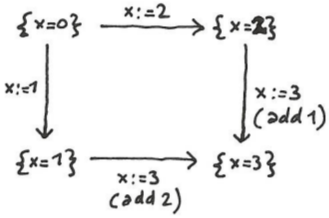
Merging Multiple Changes
There's one important aspect of conflict resolution that I've neglected so far, and that's how conflicts are resolved between lists of changes. In particular, the deltas that are actually exchanged between client and server typically contain multiple changes. Let's start with a concrete example. Suppose we have a local delta containing the following changes:
- update T1:r1 {name="James", age=9}
- update T1:r1 {pal="Leo"}
- update T1:r1 {age=10, sick=True}
And suppose we have to resolve this against this remote delta:
- update T1:r1 {name="Jim"}
- update T1:r1 {sick=False}
If we attempt to resolve the whole list of local changes against all of the remote changes together we quickly get a bewildering collection of rebase attempts. Now my brain hurts! Fortunately, the visual language to talk about conflict resolution that I introduced above (and borrowed from OT) was designed to keep our heads cool in this case:
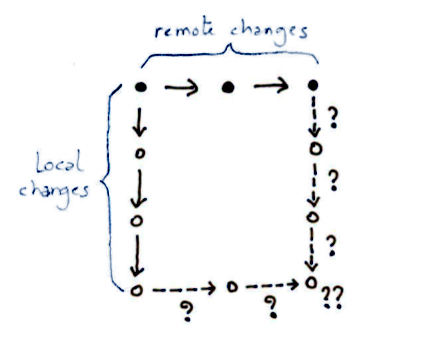
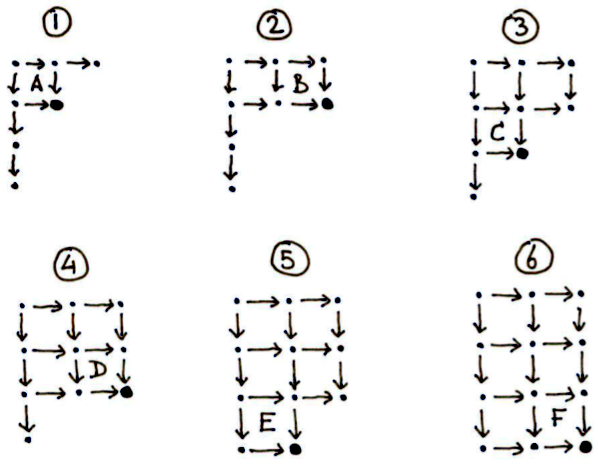
Note that the order in which you fill in the squares doesn’t really matter, except you can only fill in a square whose top and left edges are known. Here, I went strictly row by row in the diagram (A, B, C, D, E, F), but I could also go column by column (A, C, E, B, D, F), and various zig-zag patterns are also possible (e.g. A, B, C, E, D, F). In theory it’s even possible to parallelize some of the solutions: A, B|C, D|E, F.
Let me work out the final solution in the example:
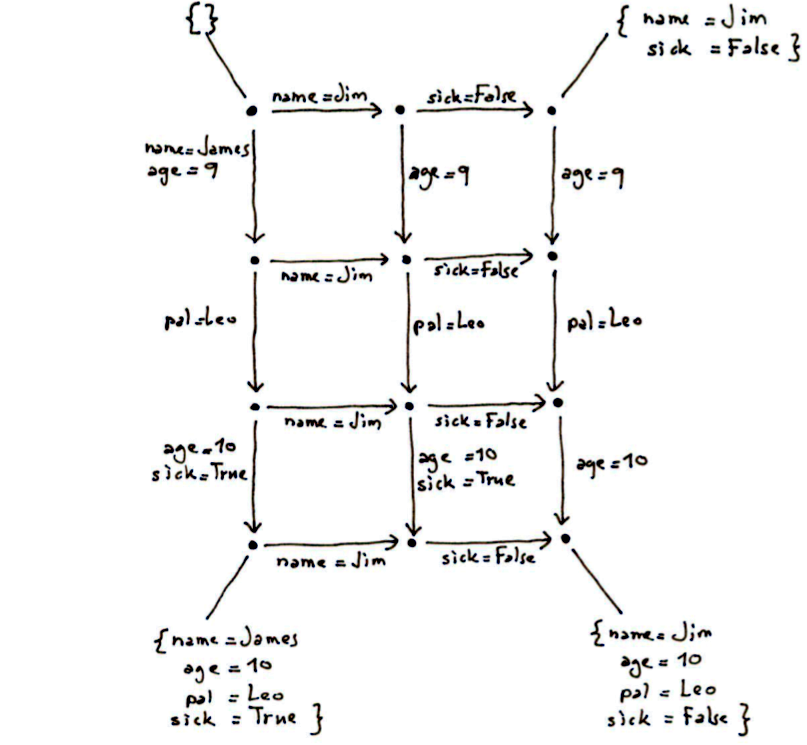
You can verify for yourself that if you take any path following arrows from the original (top left) state to the final (bottom right) state, you will always end up with the same outcome, so it is indeed valid to label the final state with a specific set of field values. The same is true for any interior state (node) that is reachable via multiple paths. I can even prove mathematically that this is so, assuming only that the basic (single-square) algorithm satisfies this property. But I won’t bore you with that. :-)
Optimizations and Simplifications
You might imagine that for deltas of realistic sizes the diagram quickly becomes very large, and that the cost of conflict resolution approaches O(N**2) for merging two sets of N changes. That's true!
Fortunately there are some observations that can save us a lot of time. For example, we can quickly determine that certain sets of changes commute trivially, for example when the table or record IDs differ, or when they affect different fields of the same record. This allows us to quickly skip over large sections of the diagram without doing any work. You can even sort the changes in each list to group changes by table and record ID (preserving the relative order of changes that affect the same record), reducing one large diagram to several unrelated, much smaller ones.
It's also likely that for most applications conflicts will be rare, since most of the time devices will be online, and when offline, users tend to use a single device. Of course, the worst-case scenario can still pretty bad. The good news is that, because of the strict mathematical nature of the basic conflict resolution algorithm, we can improve the implementation in the SDK without having to change the API or the specification. So, if you think you are running into such a worst-case scenario, let us know!
Insert vs. Update
There are many details that I've left out in the above explanation. (I figured I'd save a few things for the inevitable "Dropbox Datastores for Dummies" book. :-) One interesting issue is how the Datastore SDK deals with conflicts involving record insertions.
In case you just did a double-take, yes, record insertions can be part of a conflict, because of the API feature that lets the app choose the record ID. If you leave the record ID assignment to the SDK, you won't have to worry about this (the random numbering scheme used will unlikely produce a collision before the sun goes supernova), but if your app chooses record IDs manually you may well expect conflicts.
For example, suppose your app manages a list of contacts and you use "firstname.lastname" as your record ID. Then if a user independently inserts a contact named John Smith in two different offline devices, these inserts will be considered a conflict, since both devices assigned it the same record ID, "john.smith".
The conflict resolution code in the SDK treats this situation as follows: it breaks each insert operation into an insertion of an empty record (i.e. no fields are set), followed by an update that sets the field values. The empty record insertions commute (it doesn't matter which one we consider the "winner"), and the subsequent updates are treated as any other updates.
What if you don't want this to happen? Then you probably should leave the record ID assignment to the SDK. The two changes are then considered independent, and the datastore will end up with two records for John Smith. What you do with that is then completely up to your app.
Field Deletions
Another detail I glossed over is how field deletions are handled. There are different schools of thought about these. Some consider a field deletion a special operation, which should always win in case of a field-field conflict. This is what the SDK currently does, but there are certain problems with this approach. Fortunately we haven't heard from anyone running into those problems.
Others prefer to think of it as equivalent to setting the value to null, and resolving conflicts using the standard basic algorithm for two field updates. it is likely that we will change the SDK to use this approach. (The effect of a field deletion on the snapshot will not change — after a field is deleted, the field is deemed no longer to exist.)


